
Git’s man-pages state that it’s a stupid content tracker. It’s probably the most used version control system in the world. Which is very strange, since it doesn’t describe itself as being a source control system. And in fact, you can use git to track any type of content. You can create a Git NoSQL database for example.
The reason why it says stupid in the man-pages is that it makes no assumptions about what content you store in it. The underlying git model is rather basic. In this post I want to explore the possibilities of using git as a NoSQL database (a key-value store). You could use the file system as a data store and then use git add and git commit to save your files:
# saving a document
echo '{"id": 1, "name": "kenneth"}' > 1.json
git add 1.json
git commit -m "added a file"
# reading a document
git show master:1.json => {"id": 1, "name": "kenneth"}
That works, but you’re now using the file system as a database: paths are the keys, values are whatever you store in them. There are a few disadvantages:
- We need to write all our data to disk before we can save them into git
- We’re saving data multiple times
- File storage is not deduplicated and we lose the benefit git provides us for automatic data deduplication
- If we want to work on multiple branches at the same time, we need multiple checked out directories
What we want rather is a bare repository, one where none of the files exist in the file system, but only in the git database. Let’s have a look at git’s data model and the plumbing commands to make this work.
Git as a NoSQL database
Git is a* content-addressable file system*. This means that it’s a simple key-value store. Whenever you insert content into it, it will give you back a key to retrieve that content later.
Let’s create some content:
#Initialize a repository
mkdir MyRepo
cd MyRepo git init
# Save some content
echo {"id": 1, "name": "kenneth"} | git hash-object -w --stdin da95f8264a0ffe3df10e94eed6371ea83aee9a4d
Hash-object is a git plumbing command which takes content, stores is it in the database and returns the key
The –w switch tells it to store the content, otherwise it would just calculate the hash. the –-stdin switch tells git to read the content from the input, instead of from a file.
The key it returns is a sha-1 based on the content. If you run the above commands on your machine, you’ll see it returns the exact same sha-1. Now that we have some content in the database, we can read it back:
git cat-file -p da95f8264a0ffe3df10e94eed6371ea83aee9a4d
{"id": 1, "name": "kenneth"}
Git Blobs
We now have a key-value store with one object, a blob:
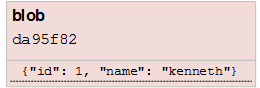
There’s only one problem: we can’t update this, because if we update the content, the key will change. That would mean that for every version of our file, we’d have to remember a different key. What we want instead, is to specify our own key which we can use to track the versions.
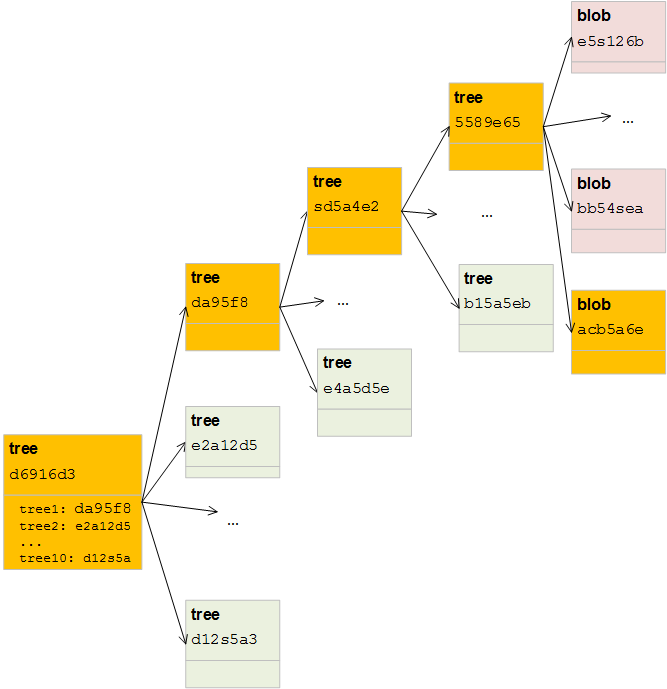
Git Trees
Trees solve two problems:
- the need to remember the hashes of our objects and its version
- the possibility to storing groups of files.
The best way to think about a tree is like a folder in the file system. To create a tree you have to follow two steps:
# Create and populate a staging area
git update-index --add --cacheinfo 100644 da95f8264a0ffe3df10e94eed6371ea83aee9a4d 1.json
# write the tree
git write-tree d6916d3e27baa9ef2742c2ba09696f22e41011a1
This also gives you back a sha. Now we can read back that tree:
git cat-file -p d6916d3e27baa9ef2742c2ba09696f22e41011a1 100644 blob
da95f8264a0ffe3df10e94eed6371ea83aee9a4d 1.json
At this point our object database looks as follows:

To modify the file, we follow the same steps:
# Add a blob
echo {"id": 1, "name": "kenneth truyers"} | git hash-object -w --stdin 42d0d209ecf70a96666f5a4c8ed97f3fd2b75dda
# Create and populate a staging area
git update-index --add --cacheinfo 100644 42d0d209ecf70a96666f5a4c8ed97f3fd2b75dda 1.json
# Write the tree
git write-tree 2c59068b29c38db26eda42def74b7142de392212
That leaves us with the following situation:

We now have two trees that represent the different states of our files. That doesn’t help much, since we still need to remember the sha-1 values of the trees to get to our content.
Git Commits
One level up, we get to commits. A commit holds 5 pieces of key information:
- Author of the commit
- Date it was created
- Why it was created (message)
- A single tree object it points to
- One or more previous commits (for now we’ll only consider commits with only a single parent, commits with multiple parents are merge commits).
Let’s commit the above trees:
# Commit the first tree (without a parent)
echo "commit 1st version" | git commit-tree d6916d3 05c1cec5685bbb84e806886dba0de5e2f120ab2a
# Commit the second tree with the first commit as a parent
echo "Commit 2nd version" | git commit-tree 2c59068 -p 05c1cec5
9918e46dfc4241f0782265285970a7c16bf499e4
This leaves us with the following state:

Now we have built up a complete history of our file. You could open the repository with any git client and you’ll see how 1.json is being tracked correctly. To demonstrate that, this is the output of running git log:
git log --stat 9918e46 9918e46dfc4241f0782265285970a7c16bf499e4 "Commit 2nd version"
1.json | 1 + 1 file changed, 1 insertions(+)
05c1cec5685bbb84e806886dba0de5e2f120ab2a "Commit 1st version" 1.json | 1 + 1 file changed, 1 insertion(+)
And to get the content of the file at the last commit:
git show 9918e46:1.json
{"id": 1, "name": "kenneth truyers"}
We’re still not there though, because we have to remember the hash of the last commit. Up until now, all objects we have created are part of git’s *object database. *One characteristic of that database is that it stores only immutable objects. Once you write a blob, a tree or a commit, you can never modify it without changing the key. You can also not delete them (at least not directly, the git gc command does delete objects that are dangling).
Git References
Yet another level up, are Git references. References are not a part of the object database, they are part of the reference database and are mutable. There are different types of references such as branches, tags and remotes. They are similar in nature with a few minor differences. For the moment, let’s just consider branches. A branch is a pointer to a commit. To create a branch we can write the hash of the commit to the file system:
echo 05c1cec5685bbb84e806886dba0de5e2f120ab2a > .git/refs/heads/master
We now have a branch master, pointing at our first commit. To move the branch, we issue the following command:
git update-ref refs/heads/master 9918e46
This leaves us with the following graph:

And finally, we’re now able to read the current state of our file:
git show master:1.json
{"id": 1, "name": "kenneth truyers"}
The above command will keep working, even if we add newer versions of our file and subsequent trees and commits as long as we move the branch pointer to the latest commit.
All of the above seems rather complex for a simple key-value store. We can however abstract these things so that client applications only have to specify the branch and a key. I’ll come back to that in a different post though. For now, I want to discuss the potential advantages and drawbacks of using git as a NoSQL database.
Data efficiency
Git is very efficient when it comes to storing data. As mentioned before, blobs with the same content are stored only once because of how the hash is calculated. You can try this out by adding a whole bunch of files with the same content into an empty git repository and then checking the size of the .git folder versus the size on disk. You’ll notice that the .git folder is quite a bit smaller.
But it doesn’t stop there, git does the same for trees. If you change a file in a sub tree, git will only create a new sub tree and just reference the other trees that weren’t affected. The following example shows a commit pointing at a hierarchy with two sub folders:

Now if I want to replace the blob 4658ea84, git will only replace those items that are changed and keep those that haven’t as a reference. After replacing the blob with a different file and committing the changes the graph looks as follows (new objects are marked in red):

As you can see, git only replaced the necessary items and referenced the already existing items.
Although git is very efficient in how it references existing data, if every small modification would result in a complete copy, we would still get a huge repository after a while. To mitigate this, there’s an automatic garbage collection process. When git gc runs, it will look at your blobs. Where it can it will remove the blobs and instead store a single copy of the base data, together with the delta for each version of the blob. This way, git can still retrieve each unique version of the blob, but doesn’t need to store the data multiple times.
Versioning
You get a fully versioned system for free. With that versioning also comes the advantage of not deleting data, ever. I’ve seen examples like this in SQL databases:
id | name | deleted 1 | kenneth | 1
That’s OK for a simple record like this, but that’s usually not the whole story. Data might have dependencies on other data (whether they’re foreign keys or not is an implementation detail) and when you want to restore it, chances are you can’t do it in isolation. With git, it’s simply a matter of pointing your branch to a different commit to get back to the correct state on a database level, not a record level.
Another practice I have seen is this:
id | street | lastUpdate 1 | town rd | 20161012
This practice is even less useful: you know it was updated, but there’s no information on what was actually updated and what the previous value was. Whenever you update data, you’re actually deleting data and inserting new one. The old data is lost forever. With git, you can run git log on any file and see what changed, who changed it, when and why.
Git tooling
Git has a rich toolset which you can use to explore and manipulate your data. Most of them focus on code, but that doesn’t mean you can’t use them with other data. The following is a non-exhaustive overview of tools that I can come up with of the top of my mind.
Within the basic git commands, you can:
- Use git diff to find the exact changes between two commits / branches / tags / …
- Use git bisect to find out when something stopped working because of a change in the data
- Use git hooks to get automatic change notifications and build full-text indices, update caches, publish data, …
- Revert, branch, merge, …
And then there are external tools:
- You can use Git clients to visualize your data and explore it
- You can use pull requests, such as the ones on GitHub, to inspect data changes before they are merged
- Gitinspector: statistical analysis on git repositories
Any tool that works with git, works with your database.
NoSQL
Because it’s a key-value store, you get the usual advantages of a NoSQL store such as a schema-less database. You can store any content you want, it doesn’t even have to be JSON.
Connectivity
Git can work in a partitioned network. You can put everything on a USB stick, save data when you’re not connected to a network and then push and merge it when you get back online. It’s the same advantage we regularly use when developing code, but it could be a life saver for certain use cases.
Transactions
In the above examples, we committed every change to a file. You don’t necessarily have to do that, you can also commit various changes as a single commit. That would make it easy to roll back the changes atomically later.
Long lived transactions are also possible: you can create a branch, commit several changes to it and then merge it (or discard it).
Backups and replication
With traditional databases, there’s usually a bit of hassle to create a schedule for full backups and incremental backups. Since git already stores the entire history, there will never be a need to do full backups. Furthermore, a backup is simply executing git push. And those pushes can go anywhere, GitHub, BitBucket or a self-hosted git-server.
Replication is equally simple. By using git hooks, you can set up a trigger to run git push after every commit. Example:
git remote add replica git@replica.server.com:app.git
cat .git/hooks/post-commit
#!/bin/sh
git push replica
This is fantastic! We should all use Git as a database from now on!
Hold on! There are a few disadvantages as well:
Querying
You can query by key … and that’s about it. The only piece of good news here is that you can structure your data in folders in such a way that you can easily get content by prefix, but that’s about it. Any other query is off limits, unless you want to do a full recursive search. The only option here is to build indices specifically for querying. You can do this on a scheduled basis if staleness is of no concern or you can use git hooks to update indices as soon as a commit happens.
Concurrency
As long as we’re writing blobs there’s no issue with concurrency. The problem occurs when we start writing commits and updating branches. The following graph illustrates the problem when two processes concurrently try to create a commit:

In the above case you can see that when the second process modifies the copy of the tree with its changes, it’s actually working on an outdated tree. When it commits the tree it will lose the changes that the first process made.
The same story applies to moving branch heads. Between the time you commit and update the branch head, another commit might get in. You could potentially update the branch head to the wrong commit.
The only way to counter this is by locking any writes between reading a copy of the current tree and updating the head of the branch.
Speed
We all know git to be fast. But that’s in the context of creating branches. When it comes to commits per second it’s actually not that fast, because you’re writing to disk all the time. We don’t notice it, because usually we don’t do many commits per second when writing code (at least I don’t). After running some tests on my local machines I got into a limit of about 110 commits/second.
Brandon Keepers showed some results in a video a few years ago and he got to about 90 commits / second which seems in line of what hardware advances may have brought.
110 commits/second is enough for a lot of applications, but not for all of them. It’s also a theoretical maximum on my local development machines, with lots of resources. There are various factors that can affect the speed:
Tree sizes
In general, you should prefer to use lots of subdirectories instead of putting all documents in the same directory. This will keep the write speed as close to the maximum as possible. The reason for that is that every time you create a new commit, you have to copy the tree, make a change to it and then save the modified tree. Although you might think that affects size as well, that’s actually not the case because running git gc will make sure to save it as a delta instead of as two different trees. Let’s take a look at an example:
In the first case, we have 10.000 blobs stored in the root directory. When we add a file we copy the tree that contains 10.000 items, add one and save it. This could be a potentially lengthy operation, because of the size of the tree.

In the second case we have 4 levels of trees, with each 10 sub trees and 10 blobs at the last level (10 * 10 * 10 * 10 = 10.000 files):

In this case, if we want to add a blob, we don’t need to copy the entire hierarchy, we just need to copy the branch that leads to the blob. The following image shows the trees that had to be copied and amended:

So, by using sub folder, instead of having to copy 1 tree with 10.000 entries, we can now copy 5 trees with 10 entries, which is quite a bit faster. The more your data grows, the more you’ll want to use sub folders.
Combining values into transactions
If you need to do more than 100 commits/second, chances are you don’t need to be able to roll them back on an individual basis. In that case, instead of committing every change, you could commit several changes in one commit. You can write blobs concurrently, so you could potentially write 1000s of files concurrently to disk and then do 1 commit to save them into the repository. This has drawbacks, but if you want raw speed, this is the way to go.
The way to solve this is to add a different backend to git that doesn’t immediately flush its contents to disk, but writes to an in-memory database first and then asynchronously flushes it to disk. Implementing this is not that easy though. When I was testing this solution using libgit2sharp to connect to a repository, I tried using a Voron-backend (which is available as open-source, as well as a variant that uses ElasticSearch). That improved speed quite a bit, but you lose the benefit of being able to inspect your data with any standard git tool.
Merging
Another potentially pain point is when you are merging data from different branches. As long as there are no merge conflicts, it’s actually a rather pleasant experience, as it enables a lot of nice scenarios:
- Modify data that needs approval before it can go “live”
- Run tests on live data that you need to revert
- Work in isolation before merging data
Essentially, you get all the fun with branches you get in development, but on a different level. The problem is when there IS a merge conflict. Merging data can be rather difficult because you won’t always be able to make out how to handle these conflicts.
One potential strategy is to just store the merge conflict as is when you’re writing data and then when you read, present the user with the diff so they can choose which one is correct. Nonetheless, it can be a difficult task to manage this correctly.
Conclusion
Git can work as a NoSQL database very well in some circumstances. It has its place and time, but I think it’s particularly useful in the following cases:
- You have hierarchic data (because of its inherent hierarchical nature)
- You need to be able to work in disconnected environments
- You need an approval mechanism for your data (aka you need branching and merging)
In other cases, it’s not a good fit:
- You need extremely fast write performance
- You need complex querying (although you can solve that by indexing through commit hooks)
- You have an enormous set of data (write speed would slow down even further)
So, there you go, that’s how you can use git as a NoSQL database. Let me know your thoughts!